В отличие от некоторых решений, где допускается низкое качество сканов, в «ЭКО-ДОК OCR» на стадию ИИ поступают изображения после предварительной очистки и фильтрации. Такой шаг является практически неизбежным, так как качество изображения сказывается и на качестве оптическое распознавание символов (OCR).
Границы ячеек и “виртуальная решетка”

Вертексы
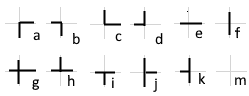
На рис 2. представлены все возможные варианты допустимых вертексов. Кроме реальных пересечений вертекс может быть пустым (пересечение реальных линий отсутствует – случай m) или ошибочным (реальная линия обрывается).
Тип вертекса кодируется целым числом (профилем).
Шаг 6 (см. рис. 1) – “Уточнение и построение профиля вертексов” заключается в корректировке положения каждого вертекса на основании бинарного изображения. Уточнение – просто вычисление сдвига по вертикали и горизонтали для каждого вертекса.
Анализ вертексов заключается в подтверждении допустимых вариантов вертексов. Например, если вертекс на вертикали отвечает профилю k, то вертексы правее могут быть только типа: m, f или j. Если ограничение не выполняется, то производится дополнительный анализ и корректировка типов противоречивых вертексов. Такой анализ, согласно benchmark (см. таблицу 1), позволяет устранить до 50% дефектов разбора таблиц.
Результаты benchmarking’а
Результаты сравнения представленного метода и его реализации с известным пакетом img2table [3] на целевом наборе из 174 страниц приведены в табл. 1. По большинству показателей представленный метод превосходит img2table.
Таблица 1. Сравнение результативности алгоритмов анализа таблиц LogStream и Img2Table.
| Показатель | Представленный метод (Logstream) | Img2table |
|---|---|---|
| Общее количество страниц | 174 | |
| Общее количество таблиц | 175 | |
| Количество ложных таблиц | 0 | 11 |
| Количество потерянных таблиц | 0 | 35 |
| Количество правильных | 161 | 65* |
| Количество ошибочных таблиц | 14 | 99 |
| Время в секундах | 380** | 265 |
| Примечание * | Результат не точный, т.к. сравнение проводилось визуально. Формализованное сравнение затруднено разным подходом к таблицам. В Logstream таблицы прямоугольные и дополняются в случае необходимости пустыми ячейками. В img2table возможны таблицы с прилегающими ячейками. Учитывались только очевидные ошибки. | |
| Примечание ** | Код Logstream не подвергался окончательной оптимизации. Алгоритмы все еще улучшаются. | |
Ложные таблицы, как правило, возникают на образах печатей и других графических элементах.
Источники
- Бутенко, Е.А., Задорожный, А.М., Любовинкина, Н.Я. и Потемкина, С.В. 2023. Система искусственного интеллекта для классификации документов сложной структуры. Системный анализ в науке и образовании. 1 (май 2023), 7–12.
- Документация по OpenCV. https://docs.opencv.org/4.x/;
Преобразование Хафа. https://docs.opencv.org/3.4/d9/db0/tutorial_hough_lines.html
- Пакет python для детектирования и анализа таблиц. img2table · PyPI]







